

 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
217 |
|||||||||||
|
Le traitement des descriptions biologiques: KATE et CaseWork |
|||||||||||
|
7.1.4.4 ConstruireFeuille (E) |
|||||||||||
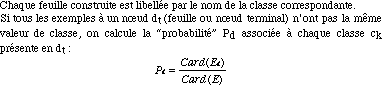
|
|||||||||||
|
A chaque libellé de classe étiquetant le noeud terminal est associé la probabilité
calculée Pd. Cette configuration correspond à une ambiguïté ou un "clash"
Cette fonction ne s'applique qu'aux attributs numériques (à valeurs ordonnées).
|
|||||||||||
|
|||||||||||
|
L'ensemble des valeurs de A prises par E est fini et noté |
|||||||||||
|
Ti |
|||||||||||
|
A chaque évaluation de Ti |
|||||||||||