

 1
2
3
4
5
6
7
8
9
1
2
3
4
5
6
7
8
9

4.2 Identification process
Given a set of examples, IKBS dynamically extracts the most efficient criteria from the ordered list of tests after each answer of the user. The cases are selected from this reply. If the answer is unknown, the second most discriminate test is proposed to the user, and so on. This procedure is the same as in KATE [13]. Nevertheless, IKBS processes cases that are in an object oriented formalism, while KATE starts from cases represented in a data table. In the former, the "exist (objects)" tests are directly exploitable at a node of the decision tree, while in the latter, these tests are deduced from the appearance of at least one not-applicable value in the object's attribute column of the table. Our approach is semantically better because it guarantees that the inapplicability of an attribute's value depends on the absence of an object and not the contrary.
An illustration of a decision tree built with 30 training cases is shown in Fig. 5. The numbers refer to previously discussed classifiers' types: taxonomic attributes (1 and 2 highlight the use of the same classifier at two different levels of the values' hierarchy), multi-valued attributes (case bulbosa with size of spines "short&long" goes in three branches (3)) and structured objects (4).
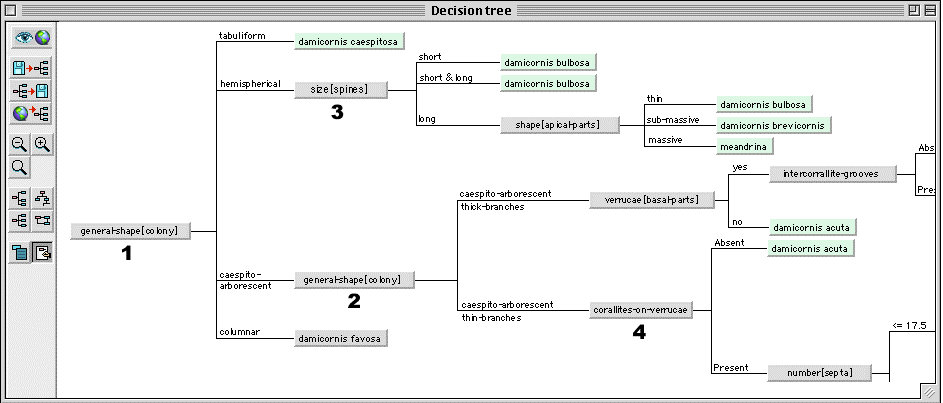
Fig. 5. Part of a decision tree that makes use of domain knowledge
5. Validation and refinement
We experimented on corals to test the reliability of IKBS identification with different users. We tested two consecutive descriptive models in a sub-domain of Pocilloporidæ: the genus Pocillopora (9 species and ecomorphs). The validation of both descriptive models was qualitative. It led to modification of the initial descriptive model (dm1) and case base to the one shown in this paper (dm2). The first test with dm1 is called A. Later, another test B on dm2 was carried out. The experiments were made with a sample of 15 specimens of the Genus, each one of them being described completely in both descriptive models by 3 different biologists (x1, x2, x3), and the expert (E). With this training set of 60 cases, the expert added 22 other descriptions of Pocillopora (37 expert cases). The four experiments that were led with IKBS are the following:
The results on 15 consultations are shown in table 1.
- A1: 15 cases of xn tested against 37 cases of E.
- A2: 15 cases of xn tested against 67 cases of (E + other xn).
- B1: 15 cases of xn tested against 37 cases of E.
- B2: 15 cases of xn tested against 67 cases of (E + other xn).
Table 1. Number of good identifications with IKBSX1 X2 X3 A1 6 7 8 A2 9 8 10 B1 9 10 11 B2 11 10 12
The results show that updating the first descriptive model and case base on Pocillopora brought better results. When testing the expert training set, it gave 20% (3/15) of improvement in identification process (from 46% to 66%). If we integrate other biologists' descriptions of the same specimens in the reference case base, the score goes up from 60% to 73%.
The reasons of these improvements are principally:
- The expert was able to detect inconsistencies in the first case base (omissions or errors in descriptions) and descriptive model (misunderstood characters, faulty illustrations). He could verify the answers of other biologists in regards to decision tree questioning that lead to misidentifications. He noticed the difficulties of interpretations of observation of specimens on some noisy comparative attributes and refined them into a new descriptive model.
- Consequently, the expert, aware of the importance of transmitting his knowledge to other biologists, postulates more precise and relevant characters that may be easier to observe and/or offer less ambiguous values (easier to interpret) in his descriptive model. For example, he will refine on the basis of mutually exclusive values, monosemic attributes, frames of reference, warning signals, enhanced illustrations.