|
|
IKBS est développé à
l’Institut de Recherche en Mathématique et Informatique Appliquée
de l’Université de la Réunion
|
Auteur : David Grosser Dernières modifications : 6 août 1998 |
Table des matières
1 - Introduction
2 - Les bases d’une méthode de gestion des connaissances descriptives
3 - Représentation des connaissances
3.1 - L’observable : le modèle descriptif
3.1.1 Les composants
3.1.2 Les attributs
3.2 - L’Observé : cas et bases de cas
4 - Classification et discrimination
4.1 - Classification
4.1.1 Gain d’information et gain ratio
4.1.2 Extensions de l’algorithme de construction d’arbres de décision
4.2 - Identification
5 - L’éditeur de modèle
5.1 - Édition d’un modèle
5.1.1 Chargement d'un modèle |
5.1.7 Mise en forme de l’arbre 5.1.8 Choix d’une racine 5.1.9 Afficher ou masquer la liste d’attributs 5.1.10 Mode édition ou visualisation 5.1.11 Création d’un objet 5.1.12 Création d’un attribut 5.1.13 Création d’une relation 5.1.14 Changer la forme des relations |
5.2 - Édition d’un objet
5.2.1 Modifier le libellé de l’objet |
5.2.4 Modifier la liste des descripteurs 5.2.5 Modifier la liste des relations 5.2.6 Associer un URL à l’objet 5.2.7 Associer un commentaire à l’objet |
5.3 - Les éditeurs d’attribut
5.3.1 L’éditeur d’attribut symbolique |
5.3.3 L’éditeur d’attribut
numérique 5.3.4 L’éditeur d’attribut de type texte |
6 - L’éditeur de cas5.4 - Tableau récapitulatif des actions souris
6.1 - Utiliser une base de cas existante
6.1.1 Charger une base de cas |
6.1.3 Naviguer dans la base de cas 6.1.4 Options d’affichage 6.1.5 Sélectionner un élément |
6.2 - Créer une nouvelle base de cas
6.2.1 Créer un nouveau cas |
6.2.4 Saisie d’une valeur multiple 6.2.5 Filtre 6.2.6 Sauvegarder la base de cas |
7 - L’éditeur d’arbre de décision
7.1 - L’arbre de décision
7.1.1 Nœud attribut
7.1.2 Nœud composant
7.1.3 Nœud de classe
7.2 - L’éditeur de décision
7.3 - Consultation de l’arbre de décision
8 - Portabilité et exécution d’IKBS
8.1 - Comment utiliser le système par Internet
8.2 - Comment utiliser le système en local
1 - Introduction
Ce document est un guide pratique d’utilisation du système IKBS version 1.1 (Iterative Knowledge Base System). Il est destiné aux utilisateurs qui souhaitent rapidement utiliser des bases de connaissances existantes ou bien développer leur propre base de connaissances.
IKBS est une plate-forme logicielle générique de construction et de gestion de bases de connaissances. Un système de gestion de base de connaissances est une application qui permet de stocker de manière structurée des informations disponibles dans un domaine donné (par exemple en biologie moléculaire, en systématique des coraux, etc). En tant que reflet d’une réalité, elle doit être robuste (bonne tolérance aux erreurs) et consistante, ce qui est une condition nécessaire pour utiliser en toute confiance son contenu. Il propose un système de représentation des connaissances descriptives dans un formalisme objet. Les connaissances de fond, appelées connaissances observables, sont représentées sous la forme d’arbres de descriptions, appelés modèles descriptifs. Les connaissances observées, appelées cas, sont représentées par des arbres possédant la même structure que le modèle et sont stockées dans des bases de descriptions, appelées bases de cas. A partir de ces données structurées, IKBS peut calculer des règles de classification représentées par des arbres de décision et générer un questionnaire en vue de l’identification de nouvelles descriptions.
Le processus de construction d’une base de connaissances n’est ni simple, ni immédiat. Il est très difficile d’établir, dès le début du processus de création, la meilleure représentation de la réalité du fait de la complexité de l’acte de modélisation. Elle requiert un processus par essais erreurs qui nécessite des remises en cause d’une partie du contenu de la base, parfois sur plusieurs niveaux de représentation. La construction est donc itérative : la connaissance s’ajoute au fur et à mesure de son obtention (des résultats d’observations, d’expériences, de calculs et de nouvelles formalisations). Le problème de l’incohérence et de l’inconsistance de la base de connaissances apparaît dans divers contextes : lorsque la connaissance du domaine évolue ou lorsque plusieurs acteurs, par exemple des experts du domaine, cherchent à mettre au point de manière coopérative une base de connaissances consensuelle.
Dans ce document sont exposés les principes méthodologiques sous jacents à la construction d’une base de connaissances robuste [2], les logiques de représentation utilisées [3] ainsi que les bases du système de classification et d’identification utilisée [4]. Ensuite, les fonctions d’édition de modèle descriptif [5], de bases de cas [6] de construction et de consultation de l’arbre de décision [7] sont détaillées. Enfin, la mise en œuvre pratique du système est détaillée pour une utilisation d’IKBS via le réseau Internet [8]. Pour utiliser rapidement IKBS, passer directement à [5].
Mots-clefs : bases de connaissances, connaissances structurées, classification, identification, arbre de décision, Internet.
2 - Les bases d’une méthode de gestion des connaissances descriptives
Les processus de construction et de gestion de base de connaissances dans des domaines évolutifs, lorsque la théorie du domaine n’est pas encore achevée, nécessitent d’adopter une démarche expérimentale. C’est le cas de nombreux domaines des sciences de la vie où les experts appliquent une méthode inductive fondée sur l’observation des faits, l’énoncé d’hypothèses et la pratique de tests expérimentaux pour mettre ces hypothèses à l’épreuve. Nous avons développé une méthodologie de gestion de bases de connaissances qui suit un développement incrémental et itérativf qui reproduit ces trois étapes de la manière suivante :
- Acquisition des connaissances : définition d’un modèle descriptif du domaine étudié puis description des cas en utilisant un questionnaire comme guide d’observation,
- Traitement des connaissances : génération d’arbres de décision par apprentissage inductif puis identification de nouvelles observations en utilisant le raisonnement à partir de cas,
- Validation des connaissances et itération : vérification de la cohérence des résultats et des descriptions par rapport au modèle de base et éventuellement remise en cause de la base de connaissances.
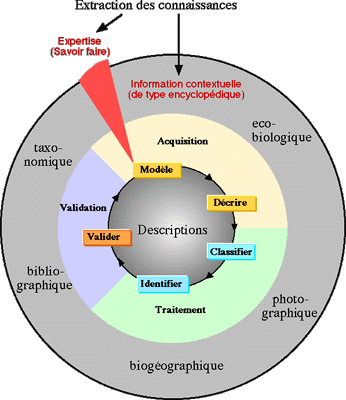
Deux types de connaissances sont distingués : les informations contextuelles et le savoir-faire de l’expert. La base de connaissances que nous construisons est constituée par un noyau d’expertise en relation avec un ensemble d’informations de différentes natures relatives au domaine (Fig.1).
Fig.1. Le processus itératif de transfert d’expertise
3 - Représentation des connaissances
Le modèle de représentation retenu à l’heure actuelle est celui d’une représentation objet-attribut-valeur. Il peut être qualifié de représentation à objet, tel que défini dans [MAS&al, 89] et [CHO, 96], dans la mesure où la notion d’élément descriptif peut être associé à la notion de classe des modèles à objets (un élément descriptif peut être décomposé et spécialisé) et les descriptions (appelées cas) peuvent être vues comme les instances d’un modèle descriptif. L’objectif majeur de ce modèle de représentation est de permettre une meilleure lisibilité que les représentations de type logique, une bonne visualisation graphique de la description des objets et enfin de nombreuses facilités de manipulation de la structure de la connaissance.
Ce modèle est également très proche des représentations utilisées dans le formalisme des objets symboliques tels que définit dans [DID, 1998].
Nous exposerons les principes conceptuels de la modélisation des connaissances descriptives, ainsi que certains des aspects pragmatiques et informatiques retenus au travers d’une implémentation dans un langage orienté objet (Java). En particulier, les hiérarchies de classes permettant de représenter un modèle descriptifs et une base de cas seront exposées.
Au niveau pragmatique, trois niveaux de représentations sont distinguées :
- Les connaissances de base ou connaissances du domaine (l’observable), représentées par le modèle descriptif du domaine.
- Les connaissances instanciées (l’observé), représentées par les cas ou instances du modèle descriptif.
- Les connaissances dérivées, produits des algorithmes d’apprentissage : arbres de décision, treillis de généralisation, règles de cohérences, etc.
Le niveau conceptuel (sémantique) sous-jacent à ces trois niveaux de représentation à été exposé dans [LE R 96] où sont exposées des "logiques descriptives" en sciences de la vie. Celles-ci définissent un cadre rigoureux permettant de modéliser un domaine, de façon naturelle, c’est-à-dire très proche de la pratique des experts.
3.1 - L’observable : le modèle descriptif
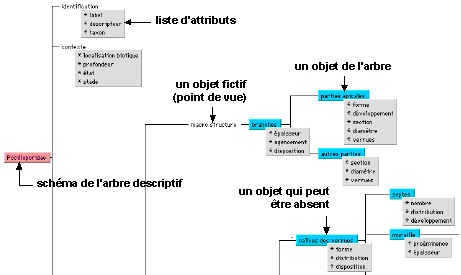
Également appelé Schéma ou arbre de description, un modèle descriptif [fig. 2] désigne une représentation abstraite, organisée (structurée sous forme d’un arbre), d’un domaine particulier. On peut considérer le modèle descriptif comme le plan d’organisation des descriptions portant sur l’ensemble des individus couverts par le domaine. La mise au point d’un modèle descriptif (arbre de description) est essentiellement un travail d’expert du domaine. Sous sa forme la plus simple, le modèle descriptif est un arbre dont chaque nœud est un objet du domaine décrit par un ensemble d’attributs et chaque relation, un lien de composition symbolisant la dépendance mutuelle des objets. Un modèle descriptif est donc composé d’éléments descriptifs, qui peuvent être soient des composants (également appelés objets) soient des attributs (ou caractères) et de relations entre ces éléments. Notons que la mise au point d’un modèle descriptif (arbre de description) est essentiellement un travail d’expert du domaine.
Fig.2 : Exemple d’arbre de description des Pocilloporidae (famille de coraux)
3.1.1 Les composants
Chaque objet de l’univers d’observation que l’expert souhaite faire apparaître peut être représenté par un composant du modèle descriptif. Cet objet peut être quelque chose de réel, concret et tangible, une partie bien identifié de l’univers d’observation. Dans une application ou l’on souhaiterait représenter les êtres humains, ce pourrait être la tête ou les bras par exemple. Cet objet peut également être un point de vue du domaine d’observation : la personne décrite vue sous le point de vue sociologique ou génétique par exemple.
Les objets sont organisés entre eux par des liens de dépendances. Ces liens ne correspondent pas à une relation d’ordre, ni à une relation hiérarchique, mais à une relation de composition. L’objet de plus bas niveau dépend de l’objet de plus haut niveau, en particulier, du point de vue de son existence. Un objet est qualifié par un autre type d’objets : les attributs. Ceux-ci portent de l’information et viennent préciser les états (ou valeurs) possibles que l’objet peut adopter. Les objets ont par ailleurs 9 états possibles donnés par la combinaison de 3 statuts :
- L’absence possible de l’objet : vrai si l’objet peut ne pas exister pour une description particulière, faux si l’objet est nécessairement présent.
- La fictivité : vrai si l’objet est un point de vue, faux s’il correspond à une entité concrète, observable.
- La multiplicité : vrai si l’objet représente une collection d’objets. Un ensemble de personnes ou une colonie de coraux par exemple.
La racine de l’arbre de description est appelée Schéma de l’arbre de description. Elle joue un rôle particulier en ce sens qu’elle est unique et que les autres objets n’existent que pour détailler, raffiner, expliciter cette racine.
3.1.2 Les attributs
La complexité des observations issues du monde réel implique la nécessité de disposer de différents types d’attributs. On voudra par exemple qu’un attribut prenne des valeurs simples ou bien multi-valuées. Les valeurs observées pourront être inconnues, absentes ou bien impossibles (on dit aussi inapplicables) selon le contexte d’observation.
Appelé également descripteur dans la littérature, chaque attribut est défini par un des quatre types de base : symbolique, taxinomique, numérique et textuel, ainsi que par un domaine de définition.
Un attribut symbolique est défini par un ensemble de symboles représentant les valeurs qu’un attribut est susceptible de prendre. Ce domaine n’a pas de structure particulière. Dès lors que ces valeurs sont liées entre elles par des relations d’ordre, l’attribut taxonomique est mieux adapté.
Selon que l’on s’intéresse à une grandeur physique : unitaire, spatiale ou temporelle, l’attribut le plus adapté est de type numérique. Un attribut numérique peut adapter des échelles. Il autorise de restreindre par des bornes inférieures et supérieures, l’espace des valeurs.
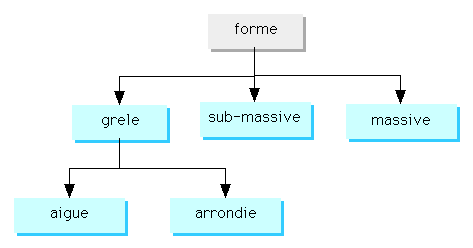
Un attribut taxonomique établi une hiérarchie de valeurs, des valeurs les plus général (plus haut niveau) aux plus précis (plus bas niveau). Le domaine de valeur d’un attribut Taxonomique est un arbre dont la racine est une pseudo valeur étiquetée par le nom de l’attribut et les composants, des objets taxonomique. Les objets taxonomiques sont donc liés entre eux, par des relations d’ordre total ou partiel. Tout objet taxonomique peut être comparé à un un autre objet taxonomique et capable de déterminer l’objet le plus spécifique commun. Cette propriété est utilisée notamment lors de la construction du graphe d’identification.
Par exemple, l’objet le plus spécifique commun des deux objets taxonomiques : aigue et arrondis est l’objet grêle.
Fig.3 : Exemple de hiérarchie taxonomique
Le quatrième type d’attribut défini dans IKBS est l’attribut texte. Cet attribut ne spécifie pas de contrainte particulière sur les valeurs. Son rôle est de représenter une information libre, sans contraintes particulières.
3.2 - L’Observé : cas et bases de cas
Un cas correspond à la description d’une observation particulière. Ce peut être un échantillon, un spécimen observé, un individu, etc. C’est une structure arborescente contenant toutes les valeurs de cette observation. L’idée majeure est qu’une Observation correspond à la représentation concrète, réelle d’un modèle, dans un contexte particulier spécifié par le modèle. En termes de conception orientée objet, on parlerait d’instanciation : un cas est une instance du modèle, dans le même sens qu’un objet est instance d’une classe. De même, une valeur est instance d’un attribut, une base d’observation est instance d’un schéma. En effet, les valeurs, les cas et les bases de cas ont toutes été créés à l’aide du modèle et n’existent que dans le contexte de celui-ci. Donc, pas de base de cas sans modèle correspondant.
Une base de cas est une instance d’un schéma, racine de l’arbre de description. C’est donc une valeur particulière, structurée et typée par un objet de type schéma. Elle référence un ensemble de cas décrits.
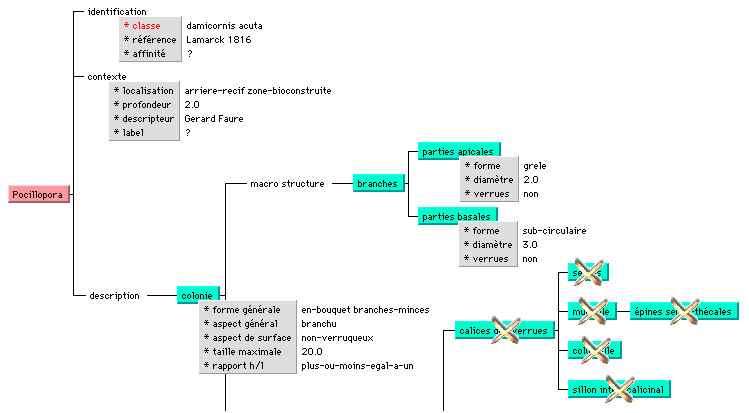
Fig.4 : Exemple d’une partie de description structurée
La figure 4 présente une partie d’une description d’un spécimen de damicornis acuta du genre pocillopora.. Le composant identification décrit l’échantillon du point de vue des caractères utiles à son identification : sa classe (nom d’espèce), la référence (Lamarck 1816) et l’affinité (l’espèce la plus proche) de l’échantillon, inconnue pour ce cas. Le composant contexte décrit différents paramètres connexes tels que la profondeur de récolte de l’échantillon, ici 2 mètres ou bien la personne qui a décrit le spécimen, appelée descripteur. Enfin, le sous-arbre de racine description correspond à la description proprement dite de l’échantillon. Notez que l’objet calices des verrues est absent ce qui induit l’absence des composants qui lui sont liés (septes, muraille, columelle, etc.), afin de conserver une cohérence logique de la description.
4 - Classification et discrimination
4.1 - Classification
Pour la classification, une procédure par arbre de décision est utilisée.
Un arbre de décision, également appelé arbre de segmentation, est un graphe acyclique orienté. Il peut être visualisé sous la forme d’un arbre (voir Fig.5) en dupliquant chaque nœud terminal en autant de fois qu’il est la cible d’une relation. Ses instances terminales représentent les classes du problème. Les nœuds internes du graphe correspondent à des descripteurs qui sont appliqués aux cas durant le processus de construction de l’arbre. Les arcs du graphe sont valués par les différentes valeurs que peuvent prendre les descripteurs, en élaguant les branches vides. La construction d’un arbre de décision se fonde sur l’optimisation d’un critère numérique local permettant de séparer récursivement un ensemble de cas en sous-ensembles généralement disjoints. L’intérêt de ce type de structure comme le souligne [Fayyad, 96] est qu’elle peut être adaptée à tout type de données et peut facilement être interprété. C’est une des techniques d’apprentissage les plus étudiée depuis les années 80.
À partir de la donnée d’une base de cas et d’un modèle descriptif, l’algorithme utilisé par IKBS propose une extension de l’algorithme classique ID3 de création d’arbres de décision [Quinlan 83]. Il est descendant, et procède pas à pas sans retour arrière. La méthode de création du graphe consiste à sélectionner pas à pas le meilleur descripteur selon un critère numérique local (ce critère peut être du gain d’information ou du type gain ratio [SHA 49], [Qui 86]), pour former un nœud du graphe. Une fois la racine identifiée, l’espace de description est subdivisé en sous-régions généralement disjointes, les segments ou nœud de décision. Un segment est donc une région de l’espace de description. Les nœuds de l’arbre représentent les différents segments obtenus par dichotomies successives et les arêtes la relation de filiation associée aux partitions. A chaque étape, la subdivision d’un segment est réalisée par une fonction binaire appelée question [voir CAR&al 1997]. La construction en profondeur est interrompue quand un certain critère d’arrêt est vérifié. Ce critère d’arrêt peut-être définit par un seuil limite préalablement fixé, par exemple un nombre minimal de cas correspondant à un nœud donné, ou bien lorsque le gain d’information de tout descripteur restant est nul.
4.1.1 Gain d’information et gain ratio
IKBS propose deux critères numériques de sélection des attributs, le gain d’information et le gain ratio. Sans entrer dans les détails de calcul du gain d’information, disons simplement que le critère du gain d’information permet de quantifier la capacité d’un descripteur à séparer un ensemble de cas en n partition. C’est donc une mesure du pouvoir séparateur des descripteurs. Cette mesure a été élaborée par Quinlan (1986) à partir des travaux de Shannon (1949). Le gain ratio est une amélioration du gain d’information classique qui permet de minimiser le biais d’apprentissage induit par les attributs possédant beaucoup de valeurs possibles. En effet, lorsqu’un attribut possède un domaine de valeur important, le partitionnement résultant est également important, ce qui provoque un gain d’information élevé pour ce descripteur qui est alors choisi comme attribut le plus discriminant. Les attributs qui ont un nombre élevé de valeurs possibles ne sont pas nécessairement ceux qui offrent le meilleur pouvoir séparateur. Il est donc souvent utile d’utiliser une mesure normalisatrice qui rectifie ce biais, comme la mesure du gain ratio.
Le système d’apprentissage d’IKBS développe certaines des extensions proposées par Quinlan [C4.5] concernant les types de descripteurs pouvant intervenir dans le processus inductif. Traditionnellement, deux types d’attributs de base sont distingués : les attributs continus (de type numérique) et les attributs discrets (de type symbolique).
4.1.2 Extensions de l’algorithme de construction d’arbres de décision
Pour les attributs dont le domaine de définition est structuré par une relation d’ordre, par exemple les attributs taxonomiques, une extension de l’induction sur les attributs discrets est proposée. La méthode consiste, lorsqu’un descripteur taxinomique est sélectionné, à créer un ensemble de partitions correspondant au premier niveau de la hiérarchie de valeur de la taxonomie. Chaque cas est affecté à la partition correspondante, de la même manière que les attributs symboliques. Ensuite, dans chacune des partitions est créé temporairement un nouveau descripteur potentiel, de type taxonomique qui possède comme domaine de valeurs, la hiérarchie de deuxième niveau de la hiérarchie initiale. Cette nouvelle hiérarchie est donc le sous-arbre de la hiérarchie initiale, dont la racine correspond à la valeur affectée à la partition. Cet attribut temporaire pourra à nouveau être choisi et discriminera selon un niveau plus précis de la taxonomie.
Lorsque les attributs sont valués par des disjonctions conjonctives de valeurs (a ET b OU C) qui permettent d’exprimer l’imprécision de variation, l’observation ainsi qualifiée est répartie dans toutes les partitions correspondant à chaque forme disjonctive contenue dans l’expression (a ET b, C). Lorsqu’une valeur est de type inconnu, l’observation correspondante est répartie dans toutes les branches. Dans les deux cas, les partitions créées ne sont plus disjointes, ce qui a pour effet de diminuer le pouvoir discriminant du descripteur. Un descripteur qui est mal renseigné dans la plupart des cas n’intervient à un nœud de décision que pour séparer le faible pourcentage de cas qui ont renseigné ce descripteur, donc tardivement. Pour un attribut symbolique, lorsque la forme conjonctive est utilisée fréquemment pour un descripteur particulier, l’ensemble des partitions est augmentée de l’ensemble des formes disjonctives possibles créées à partir des combinaisons des valeurs de base de l’attribut. Cela a pour effet d’augmenter de manière importante le nombre de partitions. Le nombre de combinaisons étant exponentiel par rapport à la taille du domaine de base. Une manière d’éviter de calculer toutes les combinaisons conjonctives de tout attribut symbolique (on ne connaît pas à priori les disjonctions qui n’apparaissent dans aucun cas) consiste à parcourir l’ensemble des cas au préalable, de manière à recenser les occurrences de formes conjonctives. Dans la pratique, il est préférable d’ajouter dynamiquement les branches correspondant formes conjonctives rencontrés, lors du premier parcours de l’ensemble des valeurs, nécessaire pour calculer le gain d’information.
Jusque-là, l’information que constituent les propriétés structurelles du modèle descriptif ne sont pas exploitées dans la procédure de discrimination. Une manière d’utiliser une partie de la connaissance structurelle consiste à établir au préalable, pour chaque objet qui peut être absents (voir III, c’est une propriété des composants) et de générer un attribut de type symbolique de domaine de valeur {présent, absent} pour cet objet particulier [voir Joclad 97]. Les descripteurs (objets et attributs) de cet objet sont considérés à ce stade, non éligibles par la procédure de discrimination, étant donné que l’objet qu’ils renseignent un objet possiblement non décrit. Ils seront éligibles une fois la présence de l’objet assurée, c’est-à-dire une fois l’attribut correspondant à la présence de l’objet choisit, et uniquement dans la partition où l’objet est présent.
4.2 - Identification
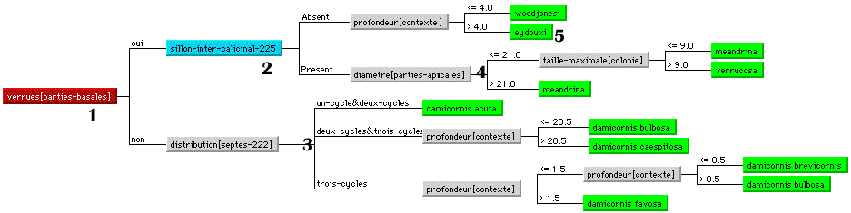
L’un des intérêts de cette méthode est que les règles d’affectation, appelées diagnoses en biologie, sont relativement simples et rapides à calculer. L’affectation d’un élément de l’espace d’observation se fait par parcours en profondeur de l’arbre de segmentation. Le cheminement suivi est déterminé par les réponses rencontrées. La classe d’affectation de l’élément est l’étiquette du segment terminal atteint en fin de parcours. La réunion des segments terminaux étiquetés par une même classe forme dans l’espace d’observation la région d’affectation de cette classe. Soit l’exemple illustré figure 4. Il présente une règle d’affectation empirique assimilable à un diagnostique portée sur l’appartenance d’un échantillon de corail à une espèce de la famille des Pocilloporidae (une des famille principale de coraux). Il a été construit à partir d’une base d’exemples de cinquante cas décrits chacun par plus de 100 attributs. La règle d’affectation peut se définir sous la forme de règles de production. Par exemple, la classe meandrina peut être caractériser par les règles suivantes :
Règle 1 : [verrues[parties-apicales]="oui"] ET [sillon-inter-calicinal="présent"] ET [diamètre[parties-apicales] > 21.0 mm]
Règle 2 : [diamètre[parties-apicales]<= 21.0] ET [taille-maximale[colonie]<=9.0 mm]
Cette écriture de la règle d’affectation montre le pouvoir explicatif de cette approche. Les règles engendrées sont facilement interprétables car elles sont écrites en utilisant le langage de description que l’expert du domaine a défini pour décrire ces données. Ainsi, les fonctions de décisions obtenues par ce type de méthode, dite de segmentation ont deux représentations principales : l’une sous-forme d’un arbre de décision, l’autre sous forme de règles de production.
Noter qu’aucune heuristique minimisant la taille de l’arbre n’a été choisit pour la construction de cet exemple (fig.5). C’est un des aspects de notre méthodologie descriptive que de privilégier la qualité des descriptions (grand nombre de descripteurs) et d’utiliser toute la richesse de celle-ci, lors de la construction de l’arbre de décision. Il est cependant possible de modifier les critères d’arrêt, ainsi que d’élaguer certaines branches de l’arbre, de manière à réduire la profondeur de l’arbre. En effet, cette démarche peut conduire à générer des arborescences trop spécifiques des exemples. Elle donne des arbres très ramifiés qui deviennent rapidement difficiles à appréhender, comme souligné dans [CAR 97], qui ont des performances anormalement optimistes sur les exemples. Il peut alors être intéressant de procéder à une phase d’élagage de l’arbre dans le but de trouver l’arbre présentant le meilleur compromis taille performance. La qualité des descriptions est également un critère à prendre en compte dans le choix du degré d’élagage.
Une autre approche proposée par IKBS utilise une information (une méta connaissance) portant sur la qualité des descripteurs du modèle descriptif. L’utilisateur a accès à cette information, mais peut choisir de laisser le système gérer lui-même ce paramètre. Celui-ci peut s’exprimer sous la forme d’un paramètre numérique ou bien sous la forme d’un treillis de nuance, exprimant l’incertitude associée à ce descripteur. L’utilisation de techniques d’apprentissage par renforcement pour équilibrer les paramètres des différents descripteurs est envisageable. Une combinaison du degré d’incertitude et d’un critère de gain d’information permet d’obtenir un arbre de décision correspondant de manière plus pertinente à la réalité que l’on cherche à caractériser, car il tient compte.
L’originalité de la procédure d’identification développée dans IKBS consiste à référencer à chaque segment l’ensemble de l’information ayant permis sa construction. La liste des cas vérifiant l’ensemble des critères préalablement visités depuis la racine, l’ensemble des critères potentiellement éligible, ainsi que leur gain d’information. Il est alors possible monter quels ont été les critères de sélection et surtout pourquoi ils ont été choisis. Le pouvoir explicatif de la méthode se trouve augmenté de la possibilité de trouver à chaque nœud du graphe d’identification la répartition des cas dans les différentes branches. Référencer la liste des attributs éligibles à chaque noeud permet également de sélectionner un autre descripteur, et donc de reconstruire manuellement une partie de l’arbre selon le nouveau critère choisi. Cette fonction est notamment utilisée lorsque l’utilisateur répond inconnu à une question particulière. La procédure d’identification choisie alors le deuxième descripteur le plus discriminant dans la liste des attributs éligibles et génère le nouveau sous arbre en conséquence.
Fig.5 : Arbre de décision (partiel) calculé à partir d’une quinzaine de cas
1 : Attribut possédant le meilleur pouvoir discriminant,
2 : Discrimination sur la présence d’un objet,
3 : Partitionnement sur un attribut multi-valué,
4 : Partitionnement sur un attribut numérique,
5 : Une feuille de l’arbre de décision correspond à une classe
5 - L’éditeur de modèle
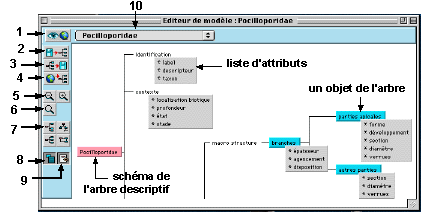
L’éditeur de modèle est la fenêtre principale d’IKBS. Cette interface permet de visualiser un modèle descriptif (appelé également arbre de description), d’éditer les différents composants de cet arbre et de créer de nouveaux composants.
Fig.6 : L’éditeur de modèle
2 - charger un modèle descriptif
3 - sauver le modèle courant
4 - charger un modèle via Internet
5 - agrandir/réduire le modèle6 - ouvrir la fenêtre de zoom
7 - mise en forme de l'arbre
8 - afficher/masquer les attributs
9 - mode édition ou visualisation
10 - liste des éléments du modèleLes options d’édition et de visualisation disponibles sont accessibles de trois manières différentes : par des actions de la souris éventuellement associées à des modificateurs (touches contrôle, majuscule, option ou commande), par l’intermédiaire de la barre de menu ou par l’intermédiaire des boutons intégrés à l’interface.
5.1 - Édition d’un modèle
La figure 6 présente une vue de l’éditeur de modèle et les boutons d’action accessibles directement. La liste des actions possibles par ce biais est présentée ci-dessous :
5.1.1 Chargement d'un modèle
Il existe plusieurs moyens d’acquérir un modèle descriptif, selon que le fichier contenant la description textuelle du modèle que l’on souhaite charger se trouve sur un disque local ou sur un serveur accessible par le réseau au moyen d’une adresse Internet, appelée URL.
Pour charger un fichier local, il faut actionner le menu fichier (voir fig.7a) et sélectionner l’item Charger modèle local.. La fenêtre standard de chargement de fichier apparaît (fig.7b). Choisissez alors le fichier que vous souhaiter charger. Ce fichier est un fichier textuel (ASCII) que vous pouvez éditer et éventuellement modifier sous n’importe quel éditeur de texte. Ceci est cependant déconseillé, il est préférable d’utiliser l’éditeur de modèle pour effectuer les modifications à apporter au modèle et sauver le nouveau modèle. Il est également possible d’ouvrir la fenêtre de fichier par l’intermédiaire du bouton fig.6 [2].
Fig.7a : Le menu d’accès aux fichiers
Fig.7b : interface choix de fichiers
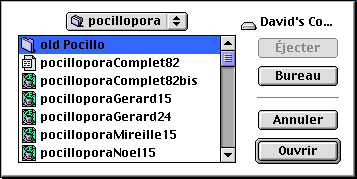
Pour charger un modèle se trouvant sur un serveur distant, il faut sélectionner l’item Charger modèle distant du menu fichier. La fenêtre de chargement d’un modèle distant apparaît (voir fig.7c) et propose une liste de modèles accessibles. Vous pouvez entrer une adresse non présente dans la liste si vous connaissez le nom complet d’accès au fichier (protocole http).
Fig.7c : Fenêtre de chargement d’un modèle distant
Il est également possible de charger des modèles prédéfinis (programmés dans l’application) par l’intermédiaire des menus Charger modèle Hyalonema (famille d’éponges marines), etc. Le résultat de l’opération est identique à l’opération précédente. Le temps de chargement est beaucoup plus rapide, mais il n’est pas possible de modifier ces modèles.
5.1.2 Sauvegarde du modèle
Il suffit de choisir le menu Sauver modèle du menu fichier, ou bien de cliquer sur le bouton fig.6 [3] ce qui a pour effet d’ouvrir la fenêtre standard de sauvegarde. Un modèle ne peut être sauvegardé directement sur un serveur distant, mais uniquement en local.
5.1.3 Effacer le modèle courant
CTRL+clic dans la fenêtre de l’éditeur permet de faire apparaître le menu contextuel de l’éditeur fig.8a. L’item tout effacer détruit tout élément du modèle courant. Une autre manière consiste à invoquer le menu contextuel des composants (contrôle + clic sur un composant) sur l’objet racine et d’activer l’item Effacer sous arbre. La même action effectuée sur un autre composant a pour effet d’effacer le sous-arbre de racine le nœud sélectionné.
fig. 8a: menu contextuel de l’éditeur
fig.8b : menu contextuel des composants
fig.8c : menu contextuel des attributs
5.1.4 Sélection d’un élément
Les éléments, objets ou attributs du modèle descriptif peuvent être sélectionnés de deux manières. Soit par un clic souris (clic gauche sur Sun et PC, simple clic sur Mac), soir par l’intermédiaire du menu déroulant [voir fig.6 [10]), en choisissant dans la liste l’élément que l’on souhaite sélectionner.
5.1.5 Agrandir et réduire la taille du modèle
Il est possible d’agrandir ou de réduire la taille du modèle soit par l’intermédiaire du menu Affichage en sélectionnant les items Zoom- et Zoom, soit par l’intermédiaire des boutons Fig.6 [5].
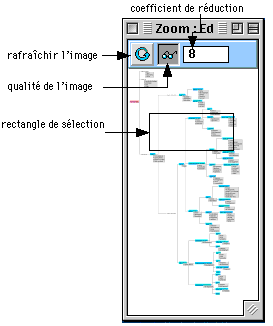
5.1.6 Navigation dans le modèle et fenêtre de zoom
Lorsque le modèle dépasse largement la taille de la fenêtre et de l’écran (grand nom d’objets et d’attributs), il devient nécessaire de pouvoir sélectionner la zone que l’on souhaite visualiser. Il existe pour cela plusieurs méthodes.
La première consiste à cliquer dans sur le fond de l’arbre ailleurs que sur un objet ou un attribut et de déplacer la souris tout en maintenant le clic, ce qui a pour effet de déplacer l’arbre tout entier, et de relâcher le bouton souris lorsque la position désirée est atteinte. La vitesse d’affichage du défilement peut être réglé au moyen de la fenêtre de réglage des préférences du menu affichage. Lorsque le mode d’affichage est positionné sur rapide, le défilement est très fluide, mais le mécanisme d’affichage utilise beaucoup de mémoire, ce qui peut occasionner des problèmes lorsque l’arbre à afficher est très grand. Le mode d’affichage moyen offre une bonne alternative entre la vitesse d’affichage et l’espace mémoire occupé, il est préconisé pour la navigation dans des arbres de grande taille.
La deuxième méthode consiste à choisir dans le menu déroulant, voir fig. 4 [10] le composant ou attribut que l’on souhaite visualiser, ce qui a pour effet de placer cet élément au centre de l’écran.
5.1.7 Mise en forme de l’arbre
L’arbre de description peut être formaté de quatre manières différentes : Arbre simple, arbre équilibré horizontal, arbre équilibré vertical ou graphe. La méthode arbre simple permet de formater l’arbre de sorte qu’il ne dépasse pas la taille de la fenêtre. Cette méthode peut être satisfaisant lorsque l’arbre n’est pas trop grand. Les méthodes arbre équilibré horizontal et verticales sont les plus adaptées dès lors que l’arbre est supérieur à la taille de la fenêtre. La méthode graphe est bien adaptée pour représenter des graphes cycliques orientés. Ces quatre méthodes peuvent êtres sélectionnés par les boutons formatage fig. 6 [7], ou bien par le menu fichier. Noter que ces méthodes ne peuvent s’appliquer que lorsqu’un objet particulier a été affecté en temps que racine de l’arbre descriptif.
5.1.8 Choix d’une racine
La plupart des fonctions d’IKBS ne fonctionnent que lorsqu’une racine (un composant particulier de l’arbre a été sélectionné. Dans ce dessein, deux méthodes sont possibles : clic sur l’objet tout en maintenant la touche option, clic avec le bouton central pour les souris a trois boutons, ou bien en activant le menu contextuel sur un objet (contrôle+clic) en choisissant l’item Affecter racine. Une fois la racine choisie, le composant racine change de couleur.
5.1.9 Afficher ou masquer la liste d’attributs
Il est possible d’afficher ou de masquer la liste des attributs de tous les composants en une action. Ceci peut être réalisé soit par clic sur le bouton fig.6 [8] ou bien par l’item afficher attributs du sous-menu attributs du menu affichage.
Fig.10 : Le menu affichage
5.1.10 Mode édition ou visualisation
Par défaut, l’éditeur de modèle se trouve en mode visualisation. Ce mode implique qu’aucune modification du modèle courant n’est possible. Il n’est pas non plus possible de créer un nouveau modèle. Ceci permet de ne pas faire de " fausses manœuvres " et d’effacer une partie de l’information par mégarde. En mode édition, toute action de modification, création ou suppression est possible. Pour passer du mode visualisation au mode édition vice-versa, deux manières : soit par clic sur le bouton fig. 6 [9], soit par action de l’item mode édition du menu Edition.
5.1.11 Création d’un objet
La création d’un nouveau composant peut s’effectuer à l’aide du menu contextuel de l’éditeur par l’item Créer objet. Ceci est également possible par un simple clic sur le fond de la fenêtre de l’éditeur en maintenant la touche option (pomme sur Mac), ou bien à l’aide du bouton droit de la souris pour les souris à trois boutons. Il est nécessaire d’éditer l’objet par la suite pour renseigner les différents champs du composant nouvellement créé. Cette option n’est disponible qu’en mode édition.
Un nom de libellé et d’identificateur sont arbitrairement affectés au composant nouvellement créé. Il faut éditer l’objet en mode édition pour pouvoir les modifier.
5.1.12 Création d’un attribut
Cette fonction n’est à l’heure actuelle disponible que par l’intermédiaire de l’éditeur d’objet.
5.1.13 Création d’une relation
Créer une relation de dépendance entre objet s’effectue à la souris en cliquant sur le composant origine de la relation tout en maintenant la touche option (ou par simple clic droit sur les souris à trois boutons) et en relâchant le bouton souris sur le composant destination. Une relation de dépendance entre le composant destination et le composant source sera créée. Noter que l’ordre dans le liste des relations définit également l’ordre d’affichage des composants de l’arbre. Pour modifier cet ordre d’affichage, il faut effacer les liens et les créer à nouveau dans l’ordre souhaité.
5.1.14 Changer la forme des relations
Les relations peuvent être visualisées de plusieurs manières : avec ou sans flèches de destination, sous forme rectiligne ou ligne brisée ou horizontales ou verticales. Ces paramètres peuvent être modifiées par l’intermédiaire du menu affichage des relations.
5.2 - Édition d’un objet
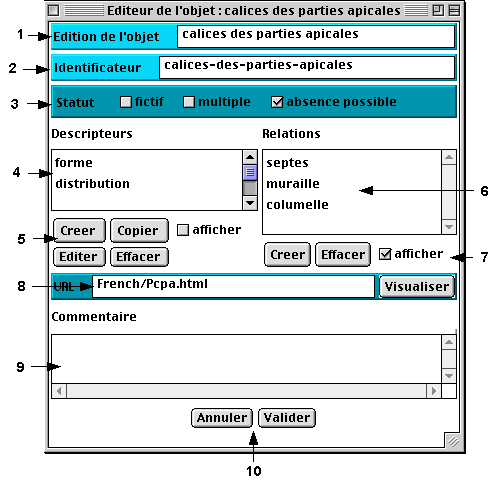
L’édition d’un objet s’effectue via le menu contextuel des objets en activant l’item Editer objet. Ceci fait apparaître la fenêtre d’édition d’objet (voir fig.11). Il faut nécessairement que le mode édition soit activé pour effectuer une modification de l’objet, sinon aucun paramètre ne pourra être modifié.
Fig.11 : Exemple d’un éditeur d’objet
2 - nom d'identificateur de l'objet (unique)
3 - statut de l'objet
4 - liste des attributs
5 - actions sur les attributs6 - liste des composants liés à l'objet
7 - actions sur les composants
8 - adresse internet de la page HTML ou de l'image illustrant l'objet
9 - commentaires associés à l'objet
10 - valider ou annuler les modificationsUn objet contient deux noms différents : un nom de libellé et un nom d’identificateur. Plusieurs objets peuvent avoir le même nom de libellé, mais il est très important que le nom d’identificateur soit unique. C’est à l’utilisateur de veiller à ce que tout objet a un identificateur unique.
5.2.1 Modifier le libellé de l’objet
Le champ texte édition (fig.11 [1]) de l’objet correspond au nom visible de l’objet. Il peut être modifié puis affecté à l’objet en actionnant la touche valider.
5.2.2 Modifier l’identificateur de l’objet
Le champ texte identificateur (fig.11 [2]) peut être modifié de la même manière que le champ édition.
5.2.3 Modifier le statut de l’objet
Le statut d’un objet peut être modifié en cochant simplement l’option fictif, multiple ou absence possible. Ces trois options peuvent être combinées pour définir par exemple un objet fictif, multiple et absent possible.
5.2.4 Modifier la liste des descripteurs
Différentes fonctions de manipulation des descripteurs associés à l’objet sont possibles
(fig.11 [7]) :
- Créer : permet de créer un nouvel attribut,
- Copier : permet de créer un nouvel attributs par duplication d’un attribut existant. Cette option n’est pas disponible dans la version actuelle,
- Editer : permet de modifier l’attribut sélectionné dans la liste,
- Effacer : efface l’attribut sélectionné.
D’autre part, il est possible d’afficher ou de masquer spécifiquement pour un objet particulier la liste de ses attributs, respectivement en cochant ou décochant l’option afficher des descripteurs.
5.2.5 Modifier la liste des relations
Il est possible d’effacer une relation en la sélectionnant dans la liste des relations de l’objet et en choisissant le bouton effacer. La boîte à cocher affichage permet de masquer tout le sous-arbre de l’objet courant. L’option créer n’est pas disponible à ce jour.
5.2.6 Associer un URL à l’objet
Le champ texte URL (fig.11 [8]) correspond au nom de l’image ou de la page HTML (page Web) associé à l’objet. Il est ainsi possible d’illustrer chaque composant d’un modèle par des images et du texte explicatif au format HTML. L’exemple illustré figure 11 indique que l’objet est illustré par la page HTML Pcpa.html située dans le répertoire French. Il est possible d’indiquer un URL complet du type : http://www.bidon.com/monImage.html.
5.2.7 Associer un commentaire à l’objet
Un commentaire peut être associé à l’objet (fig.11 [9]) pour par exemple expliciter ce que représente l’objet.
Toute modification de l’objet doit se solder par le bouton valider, auquel cas, aucune modification ne sera apportée à l’objet.
5.3 - Les éditeurs d’attribut
Il existe quatre éditeurs d’attribut différent correspondant aux quatre type d’attributs du modèle de représentation des connaissances d’IKBS : type symbolique, numérique, texte et taxonomique.
De la même manière que les composants, les attributs sont définis par un nom libellé et un nom d’identificateur unique. Ce nom d’identificateur ne doit pas contenir d’espace entre les mots se terminer par le nom du composant auquel l’attribut est lié, entre crochet. Ceci est très important, car lors de la sauvegarde et le chargement du modèle, les attributs sont associés aux objets par l’intermédiaire de ce nom d’identificateur.
A chaque attribut peut être associée une question qui sera utilisée lors de la génération du questionnaire. Si aucune question n’est associée, IKBS génère automatiquement une question du type " Quelle est la valeur de l’attribut nom de l’attribut ?".
5.3.1 L’éditeur d’attribut symbolique
Il permet de définir la liste des valeurs possible (domaine de valeurs) d’un attribut symbolique, le commentaire associé, et éventuellement une adresse URL et une valeur par défaut. Cette valeur par défaut est la valeur inconnue si aucune autre valeur n’est renseignée.
Il est possible de modifier le type de l’attribut en choisissant un autre type, auquel cas un processus de conversion sera appliqué. Un attribut symbolique peut ainsi être converti en attribut taxonomique et vice-versa, tout en conservant l’ensemble des valeurs possibles pour cet attribut.
Fig.12 : L’éditeur d’attribut symbolique
2 - nom d'identificateur de l'attribut (unique)
3 - type de l'attribut
4 - question associée
5 - domaine de valeur de l'attribut6 - commentaire
7 - pour éditer une valeur
8 - adresse HTML associée
9 - visualiser la page HTML
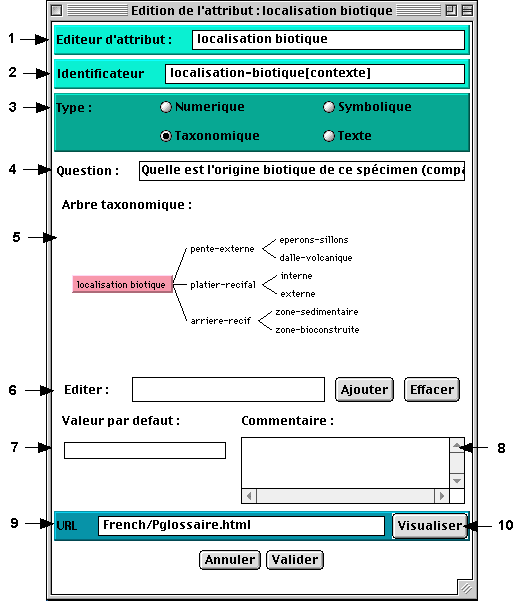
5.3.2 L’éditeur d’attribut taxonomique
Un attribut de type taxonomique est défini par un ensemble de valeur structurée par une relation d’ordre total et visualisé sous la forme d’un arbre taxonomique. La racine de l’arbre taxonomique porte le nom de l’attribut.
- Ajouter une valeur : de la même manière que pour créer un nouveau composant du modèle, il est possible de créer une nouvelle valeur par l’action contrôle + clic. Vous pouvez également taper le nom de la nouvelle valeur et ensuite l’ajouter.
- Modifier une valeur : il faut pour cela sélectionner la valeur par l’intermédiaire du menu contextuel (contrôle + clic sur la valeur). La valeur apparaît alors dans le champ éditer et peut être modifiée.
- Effacer une valeur : sélectionner la valeur et activer l’option effacer.
Fig.13 : L’éditeur d’attribut taxonomique
2 - nom d'identificateur de l'attribut (unique)
3 - type de l'attribut
4 - question associée
5 - domaine de valeur de l'attribut6 - pour éditer une valeur
7 - affecter une valeur par défaut
8 - commentaire
9 - adresse HTML associée
10 - visualiser la page HTML
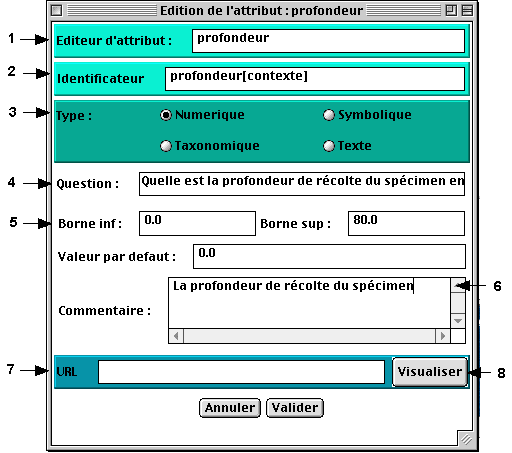
5.3.3 L’éditeur d’attribut numérique
Un attribut de type numérique est défini par un intervalle de valeur. Les champs borne inférieur et borne supérieur permettent de contraindre le domaine des valeurs possibles. Si aucune borne n’est renseignée, aucune contrainte ne sera appliquée.
Fig.14 : L’éditeur d’attribut numérique
2 - nom d'identificateur de l'attribut (unique)
3 - type de l'attribut
4 - question associée
5 - bornes du domaine de valeur de l'attribut6 - commentairepour éditer une valeur
7 - adresse HTML associée
8 - visualiser la page HTML
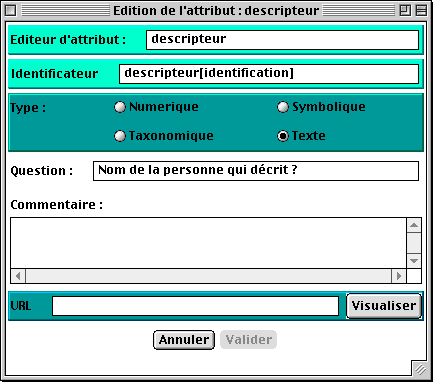
5.3.4 L’éditeur d’attribut de type texte
Seuls les champs question et commentaire associés à l’attribut peuvent être renseignés. Un attribut de type texte ne spécifie aucune contrainte sur la valeur que peut prendre cet attribut.
Fig.15 :L’éditeur d’attribut de type texte
5.4 - Tableau récapitulatif des actions souris
Modificateurs
Action souris
Résultats
Aucun
Clic et déplacement
Déplacement de la zone affichée de l’arbre
Aucun
Clic sur un objet
Sélectionner l’objet cliqué
l’objet peut être déplacé en mode éditionAucun
Clic sur un attribut
Sélectionner l’attribut cliqué
Commande ou bouton souris droit
Clic
Création d’un nouvel objet
Commande ou bouton souris droit
Cliquer sur un objet et relâcher sur un autre
Créer une relation de dépendance entre deux objets
Option ou bouton souris central
Clic sur un objet
L’objet cliqué devient la racine de l’arbre et le Schéma du modèle descriptif.
Option ou bouton souris central
Clic sur un attribut
L’attribut cliqué devient le caractère que l’on cherche à identifier lors de la procédure d’arbre de décision (la cible du système inductif)
Contrôle
Clic
Activation du menu contextuel de l’éditeur (voir fig.8a)
Contrôle
Clic sur un objet
Activation du menu contextuel des objets (voir fig. 8b)
Contrôle
Clic sur un attribut
Activation du menu des attributs (voir fig.8c)
Majuscule
Clic sur un objet et déplacement
Déplacement du sous-arbre de racine l’objet sélectionné
Contrôle + majuscule
Clic sur un objet
Effacement du sous-arbre de racine l’objet cliqué
Noter que les modificateurs utilisés suivent une certaine logique :
- La touche commande (ou bouton droit) est associée à des actions de création (de composant ou de relation),
- La touche contrôle est associée à des appels de menu contextuel,
- La touche majuscule est associée à des actions effectuées sur un sous-arbre (déplacement et effacement).
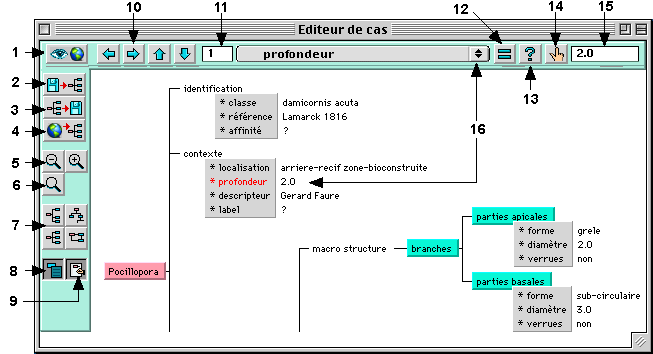
6 - L’éditeur de cas
L’éditeur de cas permet de visualiser et de modifier une base de cas. Cette interface est ouverte à partir de l’éditeur de modèle en par l’item afficher base de cas du menu cas.
Fig.16 : L’éditeur de cas
2 - charger une base de cas
3 - sauver une base de cas
4 - charger une base de cas via Internet
5 - réduire / agrandir
6 - ouvrir la fenêtre de zoom
7 - mise en forme de l'arbre
8 - afficher/masquer les attributs9 - mode édition ou visualisation
10 - navigation dans la base de cas
11 - numéro du cas courant
12 - affecter la valeur
13 - valeur inconnue
14 - filtre
15 - saisie
16 - attribut sélectionné
6.1 - Utiliser une base de cas existante
Il est nécessaire d’avoir chargé au préalable le modèle descriptif correspondant à la base de cas que vous souhaitez utiliser.
6.1.1 Charger une base de cas
De la même manière que pour charger un modèle descriptif, il existe plusieurs moyens d’acquérir une base de cas, selon que les données se trouvent sur le disque local ou sur un serveur accessible par Internet.
En local, l’action sur le bouton Fig.16 [2] ou sur le menu Fichier — Charger base de cas locale de l’éditeur descriptif ouvre la fenêtre d’accès aux fichiers contenant les bases de cas. Choisissez alors une base de cas et l’item afficher base de cas du menu cas de l’éditeur descriptif pour afficher la base de cas que vous venez de charger.
A distance, l’action sur le bouton Fig.16 [4] ou sur le menu Fichier — Charger base de cas distante de l’éditeur descriptif ouvre la fenêtre d’accès aux fichiers disponibles sur les serveurs IKBS. Vous pouvez également coder une adresse complète correspondant à une base de cas accessible par les réseaux, mais non référencée.
6.1.2 Fusionner une base de cas
Même méthode que pour charger une base de cas, sauf que si une base de cas à déjà été chargée préalablement, les deux bases de cas sont fusionnées.
6.1.3 Naviguer dans la base de cas
Le panel de navigation Fig.16 [10] permet de se déplacer dans la base de cas de la manière suivante :
Retour au cas précédent. Aucun effet si le cas courant est le cas n°1.
Aller au cas suivant. Aucun effet si le cas courant est le dernier.
Retour au cas n°1.
Aller au dernier cas.
Le champ Fig.16 [11] permet d’aller directement numéro du cas entré. Pour cela, entrer le numéro du cas et valider par la touche Retour.
6.1.4 Options d’affichage
Les options d’affichage disponibles (agrandir, réduire, afficher les attributs, etc.) sont équivalentes à celles qui sont proposées pour l’éditeur descriptif.
6.1.5 Sélectionner un élément
Deux méthodes sont possibles :
- Cliquer sur l’attribut ou le composant. Ceci a pour effet de dessiner l’élément en rouge, et de positionner le liste des éléments Fig.16 [16] sur l’élément choisit.
- Choisir dans la liste des éléments Fig.16 [16]. Ceci a pour effet de dessiner l’élément en rouge et de centrer le composant choisit au centre de la fenêtre.
6.2 - Créer une nouvelle base de cas
Pour créer une nouvelle base de cas, il suffit d’ouvrir l’éditeur de cas. Un nouvel éditeur de cas apparaît ne contenant aucun cas.
6.2.1 Créer un nouveau cas
Actionner l’item nouveau cas du menu Cas de l’éditeur de cas. Un nouveau cas apparaît ne contenant que des valeurs inconnues.
6.2.2 Effacer un cas
Actionner l’item effacer cas du menu Cas de l’éditeur de cas. Le cas courant est effacé de la base.
6.2.3 Affecter une valeur
Il faut dans un premier temps sélectionner l’attribut que l’on souhaite renseigner. Selon le type de l’attribut sélectionné, la barre d’outil s’adapte. Il y a cinq barres d’outils adaptables disponibles correspondant aux quatre types d’attributs et au type composant. Dans un deuxième temps, choisir ou entrer la valeur dans le champ (pour les attributs de type Texte ou les numériques) puis actionner le symbole =.
La barre d’outil des composants permet de mentionner que le composant sélectionné est présent ou absent, si c’est un composant qui peut être absent (Fig.17a). Si la valeur est inconnue, il suffit d’actionner le symbole ?.
Fig.17a : Barre d’outil des composants
La barre d’outil des attributs taxonomiques permet d’affecter la valeur de l’attribut sélectionné par une des valeurs de l’arbre taxonomique.
Fig.17b : Barre d’outil des attributs taxonomiques
Fig.17c : Barre d’outil des attributs numériques
Fig.17d : Barre d’outil des attributs symboliques
Fig.17e : Barre d’outil des attributs de type Texte
6.2.4 Saisie d’une valeur multiple
Lorsque l’attribut (de type symbolique dans la version 1.1 d’IKBS) sélectionné appartient à la liste des attributs d’un objet multiple, il est possible de renseigner sa valeur par une conjonction de valeur (valeur multiple), ce qui permet d’indiquer que plusieurs valeurs sont observées simultanément (conjonction de variation). La liste des conjonctions de valeurs possibles est automatiquement créée et disponible dans la liste des valeurs possibles.
Exemple : soit un attribut A de type symbolique avec comme domaine de valeur D = {a, b, c}. Si A appartient à la liste des attributs du composant C qui a comme statut multiple (composant correspondant à un ensemble d’objet observables), alors la liste des valeurs possible est :
V = {a, b, c, a&b, a&c, b&c, a&b&c}
6.2.5 Filtre
Le filtre Fig.16 [14] permet de filtrer la base de cas, c’est à dire ne conserver dans l’éditeur de cas que les cas qui correspondent à la valeur entrée. Les critères peuvent être cumulés. Pour rétablir la liste des cas initiale, il faut fermer l’éditeur de cas et l’ouvrir à nouveau.
Exemple : Je dispose d’une base de cas de 1000 spécimen de coraux décrits par 3 personnes : Gérard, Mireille et Noël. Je souhaite ne conserver que les cas décrits par Mireille dont la classe est eydouxi. Je sélectionne tout d’abord l’attribut descripteur de l’objet Contexte, j’entre le Mireille dans le champ de saisie des attributs de type Texte, puis j’actionne l’option Filtre. Ma base de cas ne contient alors plus que les cas décrits par Mireille. Ensuite, je sélectionne l’attribut classe, je sélectionne la valeur eydouxi et j’actionne à nouveau l’option Filtre. Je ne dispose alors plus que des cas décrit par Mireille de class eydouxi.
Cette sous-base peut alors être modifiée, sauvegardée, etc.
6.2.6 Sauvegarder la base de cas
Il suffit d’actionner l’option Fig.16 [3] pour faire apparaître le menu de sauvegarde et d’entrer le nom de la base. Il est conseillé d’utiliser un nom composé par le nom du modèle et le nombre de cas décrits dans la base.
La base de cas est sauvegardée sous la forme d’un tableau de données qui peut être ouvert sous n’importe quel tableur.
La première ligne contient l’ensemble des attributs du modèle.
La deuxième ligne contient le type des attributs.
Chaque ligne à partir de la troisième contient la description d’un cas.
Les caractères séparateurs des valeurs sont des tabulations.
7 - L’éditeur d’arbre de décision
Pour utiliser la procédure de classification et d’identification, il est nécessaire qu’un modèle et une base de cas aient été définis. D’autre part, il est nécessaire de choisir une cible, c’est-à-dire de définir l’attribut que le système va chercher à caractériser. Il est alors possible de générer un arbre de décision : option générer arbre de décision du menu induction de l’éditeur descriptif. La procédure peut prendre un certain temps de calcul, proportionnel aux nombres de cas décrits dans la base (complexité linéaire) et au nombre d’attributs présents dans le modèle (complexité quadratique). Une fois la procédure terminée, l’item afficher arbre de décision du menu induction permet d’ouvrir l’éditeur d’arbre de décision (voir Fig.18).
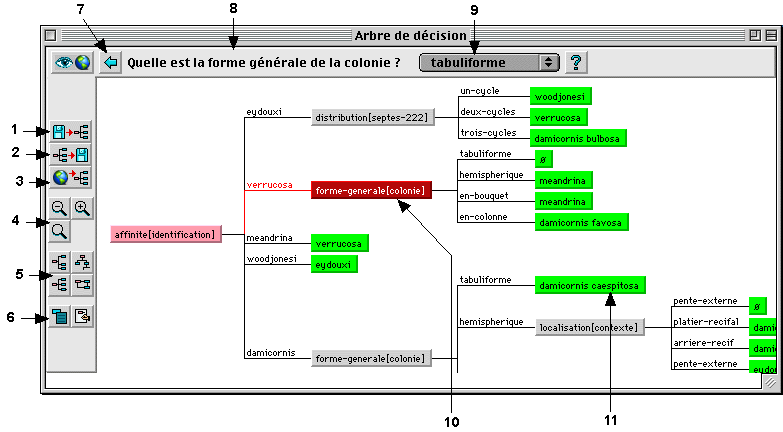
Fig. 18 : Exemple d’arbre de décision
2 - sauver l'arbre de décision
3 - charger un arbre de décision via Internet
4 - réduire / agrandir
5 - mise en forme de l'arbre
6 - options d'affichage7 - retour en arrièrere
8 - question associée à l'attribut
9 - l'attribut choisit par la fonction de décision
10 - le noeud de décision courant
11 - un noeud terminal
7.1 - L’arbre de décision
L’arbre de décision construit par IKBS est constitué d’un ensemble de nœud, que nous appelons nœud inductif. Chaque nœud inductif qui n’est pas une feuille de l’arbre est constitué d’une liste d’attributs, de la liste des gains d’information et gain ratio correspondants à chaque attribut, et de la liste des cas qui n’ont pas encore été discriminés.
L’arbre de décision construit par IKBS est composé de trois types de nœuds différents :
- Nœud attribut : l’élément le plus discriminant est un attribut.
- Nœud composant : l’élément le plus discriminant est un composant de statut absence possible.
- Nœud de classe : ce sont les feuilles de l’arbre de décision.
7.1.1 Nœud attribut
On distingue deux types de nœud attribut : les nœuds continus (de type numériques) et les nœuds discrets (de type symbolique).
Nœud continus : lorsque l’attribut est de type numérique, un seuil correspondant à la moyenne des différentes valeurs des cas est calculé. Deux partitions sont crées, l’une caractérisant les cas dont les valeurs sont supérieures au seuil, l’autre caractérisant les cas dont les valeurs sont inférieures ou égales au seuil.
Nœud discret : lorsque l’attribut est de type discret (symbolique ou taxonomique), une partition est créée pour chacune des valeurs possible du domaine, ainsi que pour toutes les combinaisons possibles
7.1.2 Nœud composant
Uniquement sur les nœud absent possible. Un nœud composant permet de discriminer les cas selon la présence ou l’absence du composant. Deux partitions sont créées : l’une caractérisant les cas pour lesquels l’objet est présent, l’autre pour les cas dont l’objet est absent.
7.1.3 Nœud de classe
Chaque feuille de l’arbre correspond à une valeur de la classe et est étiquetée par le nom de la valeur.
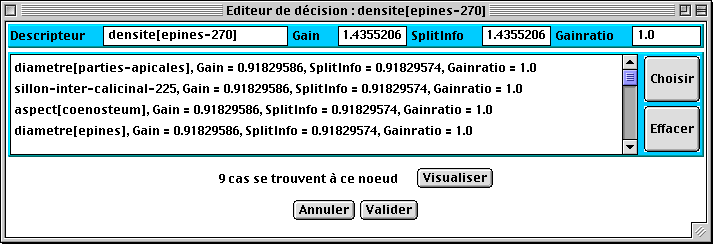
7.2 - L’éditeur de décision
L’éditeur de décision permet d’observer la liste des attributs discriminants pour un nœud donné, la liste des gains et gains ratio calculés pour chacun de ces attributs, ainsi que de visualiser l’ensemble des cas discriminés à ce nœud (voir fig. 19). Il est accessible par l’intermédiaire du menu contextuel (contrôle + clic) sur un nœud inductif.
Fig.19 : Exemple d’éditeur de décision
2 - retour en arrière
3 - question associée à l'attribut courant4 - liste des réponses possibles
5 - réponse inconnueIl est possible d’effacer un attribut en le sélectionnant dans la liste et en activant l’option Effacer suivit de Valider. Il est également possible de choisir un autre attribut - qui n’est pas le plus discriminant — en le sélectionnant dans la liste, en activant l’option Choisir puis Valider. Enfin, l’option Visualiser permet d’ouvrir un éditeur de base de cas contenant l’ensemble des cas présents à ce nœud.
7.3 - Consultation de l’arbre de décision
L’arbre de décision peut être consulté de manière interactive à l’aide d’un questionnaire dans le but d’identifier un nouvel échantillon.
A chaque nœud inductif correspond la question qui a été renseignée dans le modèle pour l’attribut sélectionné. L’utilisateur peut alors donner une réponse de deux manières. La première consiste à actionner la liste des valeurs possibles (fig.20 [4]) et à positionner la liste sur la valeur correspondant à son observation. Une nouvelle question correspond au nœud inductif correspondant à la réponse donnée sera alors posée jusqu’à ce qu’une feuille de l’arbre soit atteinte. Une réponse est alors apportée à l’utilisateur. Une deuxième méthode pour répondre aux questions consiste à cliquer directement dans l’arbre de décision sur le nœud inductif où l’on souhaite se positionner.
A tout moment, si la question ne trouve pas de réponse, l’utilisateur peut actionner l’option inconnu : ? (voir fig.20 [5]). Auquel cas, l’arbre sera modifié dynamiquement par le système et une nouvelle question sera posée.
Fig.20 : Aperçu du questionnaire
8 - Portabilité et exécution d’IKBS
Le programme IKBS v1.1 est développé en langage Java 1.1 afin de pouvoir être utilisé sur tout système d’exploitation supportant un interpréteur Java 1.1 standard. En effet, le langage Java a cette particularité que le code exécutable de l’application n’est pas spécifiquement créé pour une machine physique précise ou pour un système d’exploitation particulier, à l’inverse de beaucoup d’autres langages classiques tels que le langage C ou Pascal, mais pour une machine virtuelle Java, appelé interpréteur. Java offre de plus la possibilité de développer des applications (appelées applets) destinées à être exécutées par l’intermédiaire d’un navigateur Web (Netscape, Internet Explorer ou HotJava) dont les dernières versions intègrent un interprète Java 1.1.
8.1 - Comment utiliser le système par Internet
IKBS est une applet Java et peut donc être utilisée avec uniquement un navigateur et un accès Internet, en accédant au site Web de l’Université de la Réunion , à l’adresse :
http://www.univ-reunion.fr/~ikbs
À noter que lors que l’utilisation distante d’IKBS ne permet pas de sauvegarder les modifications apporter aux modèles disponibles, pour des raisons de sécurité.
8.2 - Comment utiliser le système en local
Vous devez disposer pour cela du logiciel IKBS sur votre ordinateur ainsi que d’un interprète Java 1.1 (Apple MRJ2.0 sur MacIntosh, HotJava sur PC ou bien le JDK1.1 sous Unix) ou bien d’un navigateur Web. L’applet IKBS se lance à partir du fichier ikbs.html que vous devez ouvrir à partir du navigateur ou de l’interprète JAVA.
[ Page d'Accueil | Coraux des Mascareignes | Page d' IKBS | Présentation | Top ]
© IREMIA - Equipe IKBS - 08/1998